Data Science/자연어 처리
자연어 처리
Boxya
2025. 4. 10. 20:57
[KT] AIVLE SCHOOL 12일차
자연어 처리
- 컴퓨터가 인간의 언어를 이해, 생성, 조작할 수 있도록 해주는 인공 지능(AI)의 한 분야
- 텍스트(비정형 데이터)를 정형화된 데이터로 바꾸는 과정
- 컴퓨터가 인식하는 데이터는 숫자
- 주요 응용 분야
- 기계 번역(Machine Translation, MT) e.g. Google 번역, Papago
- 챗봇 및 음성 비서(Chatbots & Voice Assistants) e.g. ChatGPT, Siri, Google Assistant
- 감성 분석(Sentiment Analysis) e.g. 고객 리뷰 분석, SNS 감정 분석
- 정보 검색 및 추천 시스템(Information Retrieval & Recommendation)
- e.g. 검색 엔진(Google), 유튜브/넷플릭스 추천 시스템
- 문서 요약 및 자동 생성(Summarization & Text Generation) e.g. 뉴스 요약, AI 기반 기사 작성
- 자연어 처리의 어려움(Challenges)
- 모호성(Ambiguity)
- 같은 단어라도 문맥에 따라 다른 의미를 가질 수 있음
- e.g. "배가 아프다" (신체적 통증) vs "배를 타고 떠나다" (교통수단)
- 언어의 복잡성(Complexty)
- 문법 규칙이 많고 예외가 많음
- e.g. 한국어의 조사(이/가, 을/를) 변화
- 데이터 부족 및 편향(Data Scarcity & Bias)
- 특정 언어(소수 언어)는 데이터가 부족하거나 편향된 데이터가 존재할 수 있음
- 문맥 이해(Context Understanding)
- 긴 문맥을 이해하고 유지하는 것이 어려움
- e.g. "그는 어제 그녀를 만났다. 그녀는 매우 기뻤다." -> "그녀"가 누구인지 컴퓨터가 파악하기 어려움
- 자연어 처리의 발전
- 전통적인 NLP 기법
- Rule-based Approach(규칙 기반) -> 문법 규칙을 이용한 처리
- Statistical NLP(통계 기반 NLP) -> 확률 및 통계 모델(n-gram, Hidden Markov Model 등)
- 현대 NLP 기법
- 딥러닝 기반 NLP -> RNN, LSTM, Transformer 등의 신경망 모델 활용
- 대규모 사전학습 모델(Pre-trained Language Models) -> BERT, GPT, T5 등의 모델 등장
- 전통적인 NLP 기법
- 모호성(Ambiguity)
용어 정의
- 단위
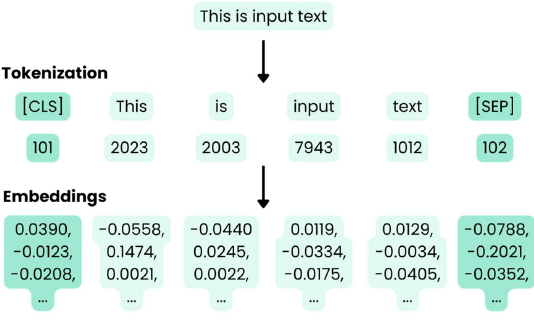
- 토큰(token) : 자연어를 처리하는 최소 단위, 문장에서 분리된 단어, 형태소, 혹은 서브 워드 단위
- 문장(sentence) : 여러 개의 토큰으로 구성된 문장 단위
- 문서(Document) : 여러 개의 문장으로 구성된 하나의 글
- 말뭉치(Copus) : 여러 개의 문서가 모인 거대한 테스트 데이터셋
- 어휘 집합(Vocab) : 코퍼스(말뭉치)에서 등장한 중복되지 않은 토큰들의 집합
- 처리
- 토크나이즈(Tokenize) : 텍스트를 작은 단위(토큰)로 분리하는 과정
- "나는 학생입니다." -> ["나는", "학생", "입니다."]
- 형태소 분석(Morphologica Analysis) : 단어를 형태소(의미를 가지는 최소 단위)로 나누고 품사를 분석하는 과정
- "먹었다" -> ["먹다"(동사), "었다"(과거형 어미)]
- 불용어 제거(Stopword Removal) : 분석에 불필요한 단어(예: 조사, 접속사, 빈도 높은 일반 단어)를 제거하는 과정
- "나는 학교에 갔다." -> ["학교", "갔다"] ("나는", "에" 제거됨)
- 임베딩(Embedding) : 단어를 숫자로 변환하여 벡터 형태로 표현하는 과정(단어 간 의미적 유사성을 반영)
- king - man + woman ≈ queen
- 토크나이즈(Tokenize) : 텍스트를 작은 단위(토큰)로 분리하는 과정
자연어 처리의 기본 과정
- 입력 텍스트 수집
- 처리할 데이터를 수집하는 단계
- e.g. 뉴스 기사 수집, 소셜 미디어 데이터 크롤링, 사용자 입력 수집
- 전처리(Preprocessing)
- 입력 데이터를 모델이 이해할 수 있는 형태로 변환하는 과정
- 핵심 작업
- 텍스트 정제(특수 문자 제거, 소문자 변환)
- 형태소 분석(의미 단위로 분해)
- 토큰화(텍스트를 기계가 이해할 수 있는 단위로 분리)
- 특징 추출(Feature Extraction)
- 전처리 된 텍스트를 벡터 형태로 변환해 모델에 입력할 수 있도록 만드는 과정
- 사용되는 기법
- BoW, TF-IDF
- Word2Vec, GloVe, FastText
- 모델에 포함된 embedding layer
- 모델링(Modeling)
- 기계학습 또는 딥러닝 알고리즘을 활용해 데이터를 학습시키는 과정
- e.g. RNN, LSTM, Transformer 기반 모델
- 출력 생성(Output Generation)
- 학습된 모델이 새로운 데이터에 대해 예측하거나 필요한 결과를 생성하는 단계
- e.g. 분류 결과, 번역된 텍스트, 요약 결과
모델링을 위한 전처리의 핵심 두 가지
- 토큰화 : 적절한 단위로 쪼개라
- 임베딩 : 각 토큰의 의미를 담아라