Data Science/생성형 AI
LangGraph 기반 Agent 시스템 (3)
Boxya
2025. 4. 24. 20:11
[KT] AIVLE SCHOOL 22일차
Memory
- AI Agent가 이전 상태(state)나 대화 기록을 유지하고 재사용할 수 있도록 하는 기능
- 유저와 AI 간의 대화를 저장하여 지속적인 맥락을 유지
- 단순한 세션 메모리 뿐만 아니라 외부 저장소를 활용하여 장기적인 상태를 저장
- 단기기억과 장기기억 정보를 제어하기 위한 로직을 넣을 수 있음
두 가지 종류의 메모리
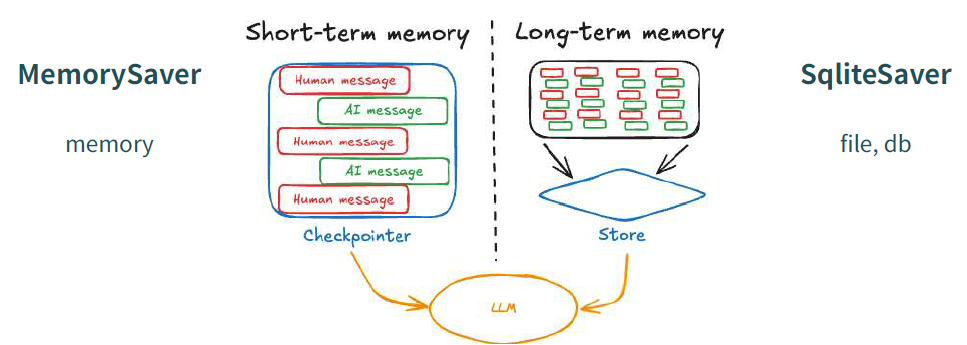
Short-term Memory : MemorySaver
- LangGraph에서 제공하는 체크포인트(Checkpoint) 저장소
- 그래프 실행 중 생성되는 상태(state)를 자동으로 저장하고 필요 시 복원할 수 있게 해주는 메모리 기반 저장소
- 주요 특징
- 용도 : 그래프의 실행 상태(state)를 저장하고 복원
- 저장 위치 : Python의 메모리(RAM) 안에 저장 (디스크 X)
- 사용 방식 : LangGraph compile() 시 checkpointer로 넘김
- 이어서 실행 : 이전 실행의 마지막 상태부터 재실행 ㄱ능
- 한계 : 세션이 종료되면 저장된 상태는 사라짐 (휘발성)
- 메모리 세팅 절차
- 메모리 준비 -> 컴파일 -> 스레드 지정 -> 실행
- 메시지를 계속 쌓을 때 생기는 문제 3가지
- 컨텍스트 초과 오류 (Context Overflow)
- GPT는 입력 길이에 한계(token limit)가 있음
- 너무 많은 메시지가 쌓이면 오류 발생
- 이전 대화가 잘리는 문제 생김
- 속도 저하 & 비용 증가
- 메시지가 많아질수록 매번 LLM 호출 시 처리 시간이 느려짐
- API 호출 비용도 계속 늘어남
- 기억이 모호해짐
- GPT가 최근보다 과거 메시지에 주목할 수도 있음
- 대화 흐름이 헷갈리거나 엉뚱한 답변이 나올 수 있음
- 컨텍스트 초과 오류 (Context Overflow)
- 이를 해결하기 위한 두 가지 방안
- 최근 메시지만 기억
- 최근 n개만 기억하고 나머지 삭제
- 오래된 메시지 요약
- 최근 n개만 남기고 나머진 요약해서 저장
- 최근 메시지만 기억
Long-term Memory : SqliteSaver
- LangGraph가 지원하는 영구 저장소들
- FileSaver : 상태를 로컬 파일(JSON)로 저장
- SQLiteSaver : SQLite DB에 저장
- PostgresSaver : PostgreSQL DB에 저장
- WeaviteSaver : 벡터 DB 기반 저장
- RedisSaver : 빠른 캐시성 저장소
- CustomSaver : 직접 구현한 저장소
- 메모리 세팅 절차
- 설치 및 라이브러리 로딩 -> DB 생성 및 연결 -> 메모리 지정 컴파일 -> 실행
- Sqlite DB는 3가지 파일로 구성
- checkpoints.sqlite
- 메인 데이터베이스 파일
- 모든 데이터의 기본 저장소
- checkpoints.sqlite-wal
- 쓰기 로그(Write-Ahead Log)
- 최신 변경사항이 일시적으로 저장됨
- checkpoints.sqlite-shm
- 공유 메모리 파일 (Shared Memory)
- checkpoints.sqlite
- Memory에 대한 활용은 MemorySaver와 동일
LangGraph로 RAG 구현하기
- Case 1 : 간단한 RAG
- LangChain의 RetrievalQA 함수로 구현된 RAG를 LangGraph로 구성
- Case 2 : VectorDB를 tool로 사용
- Vector DB를 tool로 지정해서 RAG를 LangGraph로 구성
- GPT가 스스로 판단해서 검색할지 말지를 결정 : ReAct 스타일의 RAG 시스템
- ReAct : Reasoning + Acting
- LLM이 자기 스스로 추론(Reasoning) 하고, 필요한 경우 툴을 호출해서 행동(Acting) 하는 구조
- 단순히 프롬프트 -> 응답 형태가 아니라, 질문에 답하기 위해 외부 툴을 쓸지 말지를 LLM이 스스로 판단
- 구현 방식 : Vector DB를 LangGraph의 tool로 명시적으로 분리
- LLM 호출(call_model)과 retriever(tool)를 별도 노드로 구분
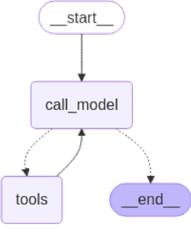
- 확장성 / 제어 유리
- 툴 추가(e.g. 웹 검색, 계산기 등)
- 복잡한 판단 로직 삽입 가능 (e.g. 분기 처리)
- Case2는 LLM이 학습한 내용에 대한 질문이나 Vector DB에 있는 질문에 답변이 가능
- 하지만 그 외의 질문에는 여전히 답변을 못함
- 이를 위해 여기에 웹 검색 도구를 포함시켜서 어떠한 질문에도 답변이 가능하도록 해야함