[KT] AIVLE SCHOOL 18일차
기존의 NLP : RNN 기반
- 오랫동안 언어모델을 위한 주요한 접근 방식
- 단점 : 병렬 처리가 어려움, 장기 의존성 문제, 확장성이 제한됨
- RNN 기반 Seq2Seq 모델
- 기존 RNN LM
- 기존 LM은 다음 단어만 예측, 혹은 분류 문제 풀기
- RNN 기반 Seq2Seq
- 입력 시퀀스를 출력 시퀀스로 변환 (e.g. 기계번역)
- 인코더(Encoder) : 입력을 벡터로 변환 (문장의 의미를 압축)
- 디코더(Decoder) : 벡터를 기반으로 새로운 시퀀스를 생성
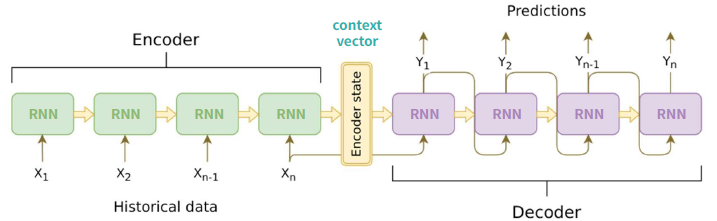
- 문제점
- 병렬 처리 문제
- 기존 RNN(LSTM) 모델들은 데이터를 순차적으로 처리 -> 병렬화가 어려움
- 문장의 앞에서부터 뒤까지 순차적으로 처리하기에 처리 속도가 느림
- 인코더의 마지막 은닉상태(context vector)를 디코더(decoder)로 전달
- 긴 문장이나 긴 데이터의 경우 문맥을 파악하는데에 한계(병목 발생)
- 장기 의존성 문제(Long-term Dependency)
- RNN(LSTM)은 긴 문장에서 앞부분의 정보를 유지하는 것이 어려움
- 긴 time step을 지나면서 초기 입려 정보가 사라지거나 약해짐
- 문장의 앞부분과 뒷부분 사이의 관계를 제대로 학습하기 어려운 문제가 있음
- 복잡한 구조 및 학습 문제
- RNN(LSTM)은 구조가 복잡하고 계산 비용이 큼
- 모델을 훈련시키는 데 시간이 많이 걸리고 최적화 어려움
- RNN(LSTM)은 구조가 복잡하고 계산 비용이 큼
- 병렬 처리 문제
- 기존 RNN LM
Transformer
- 기존의 NLP : RNN 기반
- 오랫동안 언어모델을 위한 주요한 접근 방식
- 단저 : 병렬 처리가 어려움, 장기 의존성 문제, 확장성이 제한됨
- Transformer 등장 배경
- RNN의 모델의 단점을 극복
- 언어 모델의 Game Changer
- Transformer 덕분에 LLM이 발전하게 됨
- Attention 매커니즘
- Attention : 중요한 단어(정보)에 집중하여 더 정확한 출력을 만드는 기법
- 개념
- 기존 Seq2Seq이 한계
- 인코더가 모든 정보를 하나의 Context Vector에 압축 -> 정보 손실 발생
- 입력 문장이 길어질수록 맨 앞 단어의 정보가 약해지
- Attention의 역할
- 디코더의 세번째 LSTM 셀은 출력 단어를 예측하기 위해 인코더의 모든 입력 단어들의 정보를 다시 한번 참고
- 디코더 세번째 LSTM의 히든상태와 인코더의 각 히든 상태 간 dot product
- 소프트맥스 함수 결과: I, am, a, student 단어 각각이 출력 단어를 예측할 때 도움이 되는 정도를 수치화 한 값
- 이를 하나의 정보로 담아서 디코더로 전송
- 소프트맥스 결과값을 인코더 히든상태 값에 곱하고 합쳐서(weighted sum) 디코더로 전송
- 디코더의 세번째 LSTM 셀은 출력 단어를 예측하기 위해 인코더의 모든 입력 단어들의 정보를 다시 한번 참고
- 기존 Seq2Seq이 한계
- Transformer 구조

- Transformer 주요 특징
- Self-attention : 입력 문장의 모든 단어가 서로 어떤 관계를 가지는지 학습
- 기존 Attention : Seq2Seq에서 인코더-디코더 간의 정보 전달에 초점
- Self-attention은 같은 문장 내에서 단어들 간 관계를 파악하는 것이 핵심
- RNN과 차이점 : 병렬 처리 가능
- 전체 문장을 한 번에 고려하면서 단어 간 관계를 학습
- 모든 단어가 동시에 처리 가능해서 연산 속도가 크게 향상됨
- Multi-Head Attention
- 하나의 Attention 매커니즘만 사용하지 않고 여러 개의 Attention을 동시에 수행하는 기법
- Transformer에서 핵심적인 역할을 하는 Self-Attention은 한 번만 수행하는 것이 아님
- 여러 개의 어텐션을 병렬적으로 수행한 후 이를 합치는 방식으로 동작
- e.g. "The animal that was seen by the man was a dog"
- 단순한 어텐션 : "animal"과 가장 관련 있는 단어를 찾으면 "dog"에 집중
- Multi-Head Attention
- 첫 번째 어텐션 : "animal" <-> "dog" (명사 간 관계 학습)
- 두 번째 어텐션 : " animal" <-> "seen" (동작과의 관계 학습)
- 세 번째 어텐션 : "animal" <-> "man" (소유자 관계 학습)
- ...
- 즉, 여러 개의 관점을 사용하면 더 풍부한 문맥 정보를 학습 가능
- Positional Encoding (위치 정보 인코딩) - 단어 순서 반영
- Self-Attention은 단어 간 관계를 학습하지만 순서 정보(position)가 포함되지 않음
- 이를 해결하기 위해 위치 정보(Positional Encoding)를 추가
- 작동 원리
- 각 단어의 위치를 나타내는 값을 계산하여 임베딩 벡터에 더함
- 일반적으로 sin과 cos 함수를 사용해 패턴을 생성
- 같은 위치에서는 같은 값을 가지므로 모델이 단어 순서를 학습할 수 있음
- Feed Forward Network(FFN) - 추가적인 비선형 변환을 수행
- Self-Attention을 통해 얻은 정보를 추가적으로 변형하고 학습하는 역할
- 각 단어에 대해 Self-Attention을 적용한 후 추가적인 비선형 변환을 통해 정보를 조정하는 단계
- 동작원리
- Self-Attention을 거친 벡터를 입력으로 받음
- 두 개의 Dense(완전연결) 레이어를 통과하면서 추가 변환 수행
- 활성화 함수 (ReLU) 사용
- 더 복잡한 특징을 학습할 수 있도록 함
- 필요성
- Attention을 가진 정보만으로는 단순한 변환만 가능
- FFNㅇㄹ 사용하면 비선형 변환을 추가하여 더 정교한 표현 학습이 가능
- 결과적으로, FFN은 Transformer가 더 강력한 표현력을 가질 수 있도록 도움
- Self-attention : 입력 문장의 모든 단어가 서로 어떤 관계를 가지는지 학습
- Transformer to GPT, BERT
- Transformer의 기본 구조
- Encoder : 입력 문장을 인코딩하여 벡터 표현을 생성
- Decoder : 인코더의 출력 벡터를 받아서 최종적으로 문장을 생
- Transformer의 기본 구조
| GPT Generative Pre-trained Transformer, OpenI(2018) |
BERT Bidirectional Encoder Representations from Transformers, Google(2018) |
|
| 특징 | - Transformer의 Decoder만 사용하여 만든 모델 - Autoregressive 방식으로 다음 단어를 예측하는 언어 모델 - Left-to-Right 방식으로 문장을 순차적으로 생성 - Transformer의 Decoder 블록을 반복적으로 쌓아 모델을 구성 - 이전 단어만 참고하면서 다음 단어를 예측하는 구조 - Masked Self-Attention 사용 : 미래 단어를 참조하지 않도록 - 활용 : 텍스트 생성(ChatGPT), 문장 생성 기반 태스크 |
- Transformer의 Encoder만 사용하여 만든 모델 - 양방향(Bidirectional) 문맥을 고려하여 문장을 이해 - Masked Language Model(MLM) & Next Sentence Prediction(NSP) 방식으로 학습 - 문장의 전후 문맥을 모두 고려하여 더 깊이 있는 이해 가능 - 문장 의미 파악, 문장 관계 분석 등에서 뛰어난 성능 - 활용 : 문서 분류, 질의응답(Qna), 감성 분석, 검색 엔진 개선 |
| 한계 | - 양방향 문맥을 고려 못함 -> 한 방향(L-R)으로만 단어를 예측 - 문장의 의미를 깊이 이해하는 데 한계가 있음 |
- 문장 생성을 직접 하지 않음 : GPT처럼 자연스럽게 텍스트를 생성하는 데는 적합하지 않음 - 학습 비용이 큼 : 대량의 데이터와 연산이 필요 |
GPT의 발전
- GPT는 모델 크기 확대, 데이터 다양화. 학습 방식 개선(Few-shot, Zero-shot), RLHF 도입,
- 그리고 멀티모달 지원을 통해 점점 더 강력한 자연어 이해 & 생성 능력을 갖추며 발전해 옴
BERT의 발전
- BERT는 모델 성능을 높이는 방향(RoBERTa, Electra)과 경량화하는 방향(ALBERT, DistilBERT)으로 발전해 왔음
- 최근에는 특정 도메인에 맞춰 Fine-tuning된 버전들이 활용
LLM 모델
- LLM 모델 학습의 어려움
- 연산 자원 및 인프라
- 데이터 확보
- 훈련 시간 및 반복 횟수
- 과적합 및 일반화 문제
- 유해하거나 잘못된 데이터 생성
- 환경적 영향
- LLM 활용 방법
- Modeling : 나의 데이터를 가지고 직접 학습 시킴
- 사전 학습 된 LLM
- API, huggingface : 모델 그대로 사용하기
- Fine-tuning : 나의 데이터를 가지고 추가 학습 시키기
- RAG : 나의 데이터를 가지고 답변 시키
'Data Science > 생성형 AI' 카테고리의 다른 글
| Vector DB와 RAG 파이프라인 구축 (0) | 2025.04.22 |
|---|---|
| Vector DB와 RAG (2) | 2025.04.22 |
| LangChain (0) | 2025.04.21 |
| Fine-tuning (1) | 2025.04.18 |
| LLM 활용 (2) | 2025.04.18 |