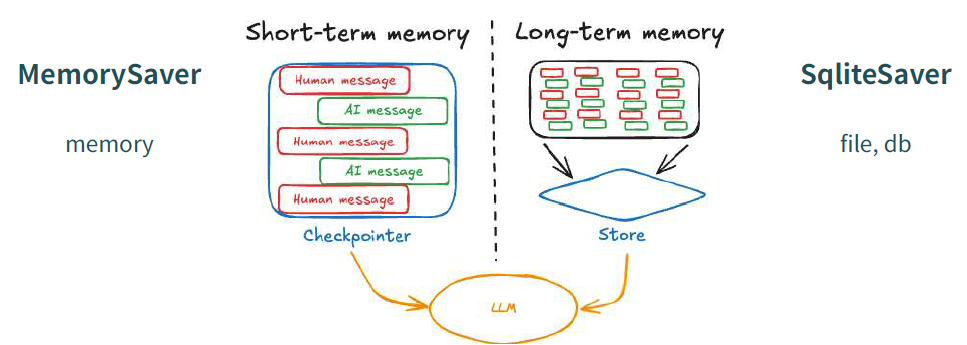
[KT] AIVLE SCHOOL 23~25일2번째 미니프로젝트는 생성형 AI 였다.먼저 1일차에는 개인적으로 그래프 구성도와 State를 정의해보고각 모듈 함수를 구현해보았고, 팀원들과 통합하였다.그리고 2일차에는 통합한 조별 파일을 가지고각각의 파트를 고도화하는 작업을 했다.마지막 3일차에는 2일차에서 보완할 점을 보완하고산출물을 작성했다. 프로젝트의 목표는 개인화된 질문과 답변에 대한피드백을 해주는 AI 면접관 Agent 시스템 구축이다.LangGraph을 기반으로 Agent 흐름을 설계하고LLM을 기반으로 질문을 생성하며 전략적 응답 흐름을 구성한다.사전 준비 절차는 이력서를 업로드하면 이력서를 요약하고 질문 전략을 수립한다.다음으로 면접 절차는 수립한 질문 전력에 맞게 생성한 질문을 제시하고 사용..