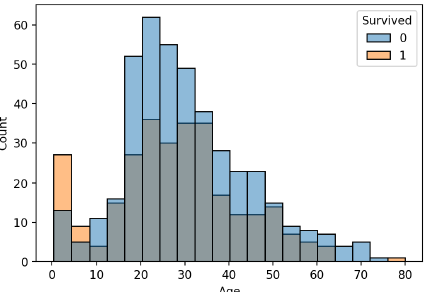
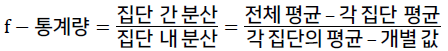[KT] AIVLE SCHOOL 6일차 시각화HistogramSeaborn의 histplot() 함수로 Histogram 생성Histrogram을 범주별로 겹쳐 그리기sns.histplot의 hue 옵션에 범주를 지정sns.hisplot(x='Age', hue='Survived', data=titanic, bins=20)plt.show()Density PlotSeaborn의 kdeplot() 함수로 Density Plot을 생성common_norm 매개변수 값을 False로 지정하면 두 그래프 각각의 면적이 1, 기본값은 Truesns.kdeplot(x='Age', hue='Survived', data=titanic, common_norm=False)plt.show()multiple = 'fill' 옵션..