[KT] AIVLE SCHOOL 14 ~ 17일차
첫번 째 미니 프로젝트는 스마트폰 센서 데이터 기반 모션 분류를 진행하였다.
가속도 센서와 자이로스코프 센서로 각각 선형가속도와 각속도를 측정한 데이터라고 한다..
무슨 말인지는 잘 모르겠지만 다행히 데이터가 기본적으로 어느정도 가공되어있었다.
하나의 센서에서 수집된 신호를 가공방법을 달리하여 집계한 데이터였고, 센서별, 집계별, 축 별로 데이터가 나누어져있어서
변수가 561개나 있었다..!!
오전에는 변수의 중요도를 구해보고, 탐색적 분석을 진행해보는 과제였다.
그래서 첫번째로 많은 Feature가 있기 때문에 변수 중요도를 구하고, 중요하거나 중요하지 않은 특징들을 골라서
탐색적 분석(EDA)를 진행하였다.
데이터 확인해보기
shape 함수로 행, 열 개수 확인 / head 로 상위 행 확인 / describe 로 수치형 변수 기초통계량 확인 / info 로 변수 확인
(변수 갯수가 많아서 결과는 pass)
위 4가지 함수는 EDA에서 꼭 확인하는 함수인 것 같다. 데이터가 주어지면 필수로 알아야하는 함수이다..!
근데 아직까지는 사실 봐도 그냥 그렇구나 정도로만 보고 넘어간다..
그리고 우리의 목표 변수인 'Activity' 라는 놈의 범주 빈도 수와 빈도 비율을 구해보았다.
value_counts 로 범주 빈도 수를 구하고, value_counts 에 normalize=True 라는 옵션을 주어 빈도 비율을 구했다.
저 옵션이 기억 안나면 빈도 수와 총 데이터의 갯수를 나누어서 출력할 수도 있다.

unique 함수로 범주 값의 종류를 파악하기

countplot 으로 범주 수 시각화하기

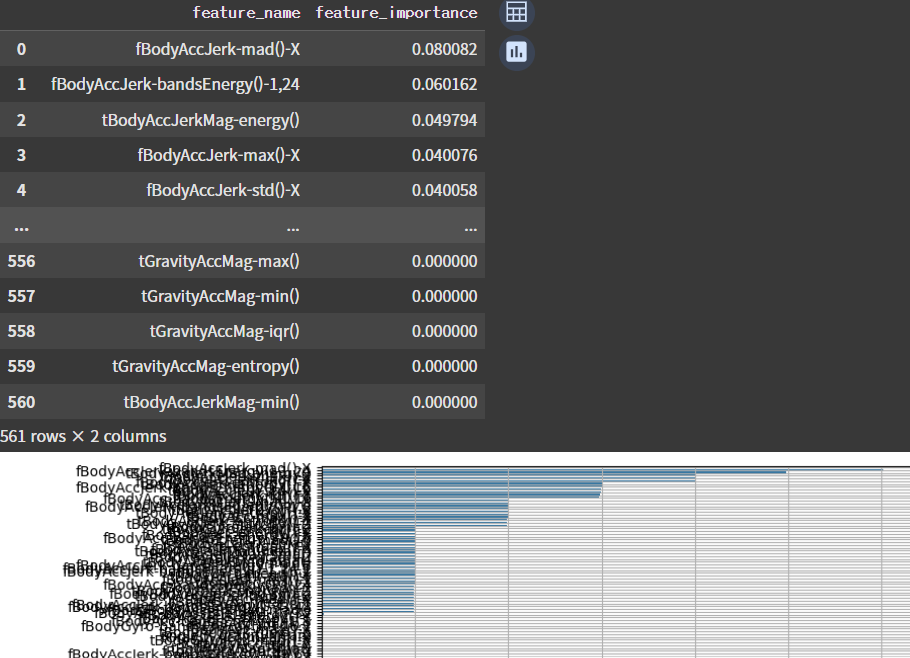
간단하게 데이터를 확인해보고, 변수 중요도를 확인해보았다.
randomforest 모델로 데이터를 학습시키고, feature_importance_라는 명령으로 변수 중요도를 구했다.
중요도 순으로 데이터를 나타내고, 그래프를 그려보았는데..
feature가 너~~~~~무 많아서 어지럽다..

내가 찾은 상위 5개는 이렇다. 나중에 팀원들과 비교해보니 모두 달랐다.

이유는 잘 모르겠지만 모델 생성 시 random_state 값이 다르거나, 혹은 feature끼리 상관계수가 높아서 그런게 아닐까..
라고 조심스레 추측해보았다.
아래는 그냥 재미삼아 상위 5개 끼리 상관분석을 해본 결과이다.

그리고 위 변수들과 target인 'Activity'을 kdeplot으로 나타내보았다.
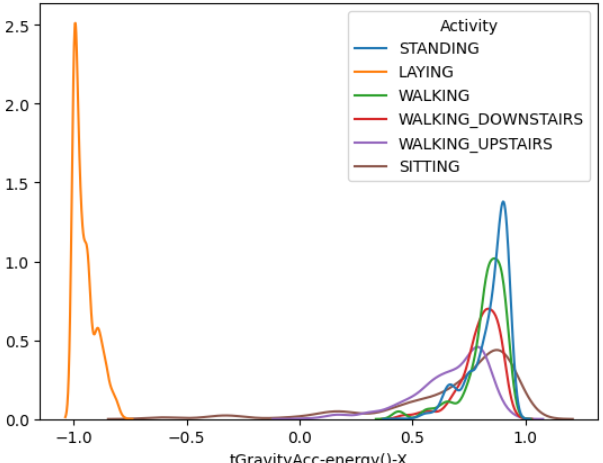
이 그래프의 그림이 어떤 것을 의미하는지는 더 공부를 해봐야할 것 같다..
kdeplot을 여러 변수들과 비교해보고
그리고 다음으로는 정적(Standing, Sitting, Laying), 동적(Walking, Downstairs, Upstairs) 행동으로 구분하고,
두 클래스 그룹을 구분하는데에는 어떤 특징(Feature)이 중요한지 찾아보고 탐색해보았다.
6개의 행동을 2개의 그룹, 정적 동적 그룹으로 나누어 보았다.
6개의 클래스가 2개의 클래스로 된 것이다.
먼저 새로운 변수를 추가하여 'STANDING', 'SITTING', 'LAYING' 일 경우 0으로,
'WALKING', 'WALKING_UPSTAIRS', 'WALKING_DOWNSTAIRS' 일 경우로 1로 저장하였다.
그러고 새로운 데이터로 데이터를 분할하고 마찬가지로 RandomForest 모델을 학습시키고
똑같이 변수 중요도를 분석해보았다.
이번에는 이렇게 나왔다.
이번에도 위와 같이 상위 하위 5개의 데이터들로
target 변수와 kdeplot를 돌려보면서 데이터들을 놀아주었다.
그리고 처음 구한 변수 중요도 데이터프레임과,
정적, 동적으로 구분한 그룹의 변수 중요도 데이터프레임을
merge(병합)해주었다.

그리고 이 결과와 features 라는 변수들의 설명이 적혀있는 파일이 있는데,
이 파일과도 merge 해주었다.

오후에는 다양한 분류 모델을 생성해보았다.
은닉층, 학습률, 에포크 등을 조율해보고, 과적합 방지 기법등을 사용한 모델들을 다양하게 설계하고 학습시켜
어느 모델이 가장 좋은지 비교해보았다.
먼저 pd.read_csv로 csv 파일을 불러와 저장한다.
그리고, 불필요한 칼럼이 있으면 삭제하였다.

그리고 EDA의 4대장 shape, head, describe, info 친구들로
분석을 해주었다.
데이터 확인이 끝나면 다음으로 데이터를 전처리하였다.
학습시키기 위해 데이터를 야무지게 요리해주는 과정이다.
먼저 target 변수를 기준으로 x, y를 나누어준다.

그리고 스케일링과 인코딩을 진행하였는데,
나는 MinMaxScaler 와 LabelEncoder를 사용하였다.
그리고 train_test_split로 데이터를 분할하였다.
본 프로젝트에서는 스케일링, 인코딩 진행 후
데이터를 분할하였는데,
빅분기를 칠때 공부한 걸로는 데이터를 먼저 분할하고
스케일링, 인코딩을 진행했던 기억이 있어서
GPT햄한테 물어보니까
테스트 데이터는 학습 과정에 절대 영향을 받아서는 안된다.
라는 얘기를 해주시면서
train_test_split를 먼저 하고
스케일링과 인코딩을 진행하라고 하신다.
이렇게 데이터를 분할하고 딥러닝 모델을 만들었다.
먼저 분할한 데이터들을 텐서 -> 텐서 데이터셋 -> 데이터로더로
변환해주었다.
그리고 모델을 설계하고 학습시켰다.
먼저 은닉층 없이 epoch를 10으로 하고 학습률을 0.001로 한
나의 모델의 학습 곡선이다.
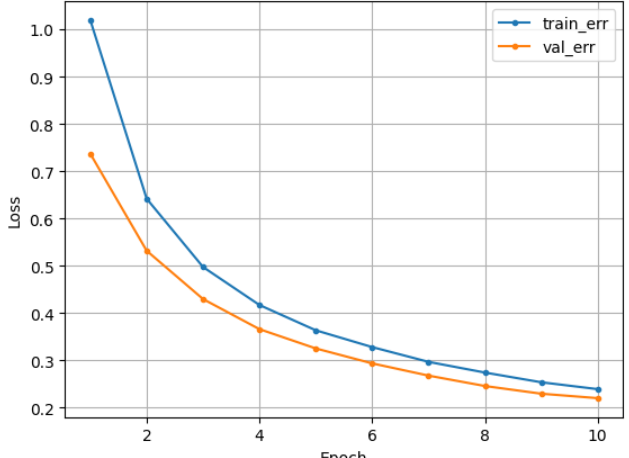
나름 귀엽게 생겼다.
그리고 은닉층을 3개 두고 epoch를 20, 학습률을 0.01로 한
모델의 학습 곡선이다.
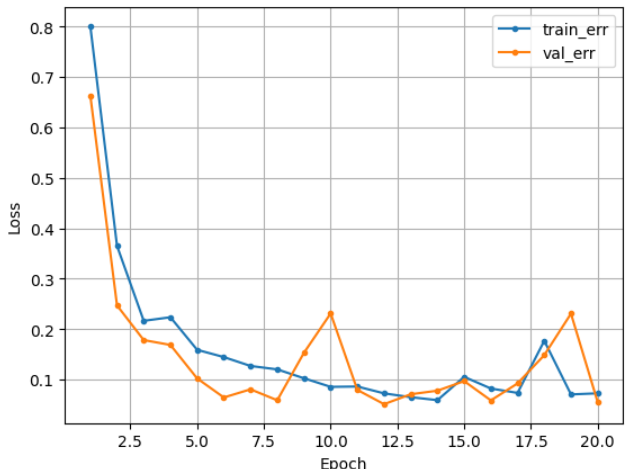
가끔 삐죽삐죽 한데 나름 나쁘지 않아 보인다.
아래는 Dropout과 Early Stopping 을 사용한 모델이다.
은닉층을 3개, epoch를 100, 학습률을 0.001로 주었다.
조기 종료되어 11번만에 끝났다.

전체적으로 다 비슷비슷한 것 같다.
다음으로는 정적, 동적 행동 분류 모델을 생성하고, 모델에서 0으로 예측 한 경우 정적 행동 3가지를 분류하고,
모델에서 1으로 예측 한 경우 동적 행동으로 3가지를 분류하는 모델링을 진행해보았다.
이 부분은 시간이 없어 다 못한 부분은 교육 이후 집에서 채워넣었다..
데이터 탐색, 분할 그리고 데이터로더로 변경하고
모델을 설계, 학습시키는 것은 똑같다.
데이터만 바꾸어주고 학습을 진행하였다.

이 모양이 맞나 싶다..

뭔가 잘못한게 틀림없어 보인다.
정적, 동적 동작을 세부 분류하는 과정에서도
학습시킬 때

이 오류가 계속 뜨는데..
데이터를 조작하는 단계에서 뭔가 잘못된 것 같다..
처음부터 코드를 확인해보면서 오류를 고쳐봐야겠다.
확실히 강의때 강사님들이 쉽게 설명해주실 때는
오류가 안나니까 괜찮았는데,
강사님 없이 할라니까 조금 어려운 것 같긴 했다.
그래도 이번에 코드들을 직접 다뤄보면서
머릿속에 개념만 희미하게 돌아다니던 녀석들이
어느정도 조금은 진해진 것 같다.
항상 실습의 효과는 대단한 것 같다.
꾸준히 실습하며 익히면서 공부하면
더 친해질 수 있지 않을까 싶다.

미니프로젝트 2일차에는 위 코드들을
팀원들과 합치고, 이에 대한 발표를 진행했다.
전체적으로 구조가 비슷했는데
변수 중요도는 조금씩 다 다르게 나왔다.
변수끼리 상관계수를 비교했을 때 너무 값이 높게 나와서
그런거 일수도 있지 않을까 라는 생각을 했고,
모델링 과정에서 하이퍼파라미터를 다르게 주어서
그런거 일수도 있지 않을까 라는 생각을 했다.
이번 미니프로젝트에서 내가 팀장을 맡아서
전체적으로 코드를 합치고, 팀원들과 발표 준비 PPT를 준비했다.
PPT를 작성할 시간이 충분하지 않아서
작성할 양식을 빠르게 구상하고 채워넣었다.
각 미션마다 미션의 목적, 핵심내용들을 넣었고
조원들끼리 달랐던 내용들을 넣었다.
그리고 미션 3~4는 대부분 모델의 성능을 비교하는 내용이여서
기본 모델, 과적합 시 모델, 적합한 성능의 모델을 넣고
각 모델의 하이퍼파라미터 조정값, 성능 결과를 넣어
모델들의 성능을 비교할 수 있도록 구성했다.
발표시간이 끝나고는
동일한 데이터로 다른 주제를 구상하는 연습을 하였다. (생성형 AI와)
1일차 때 진행한 스마트폰 센서 데이터로
다른 주제를 구상해보았는데,
나는 스마트폰 센서 데이터(앉기,서기,눕기 / 걷기, 올라가기, 내려가기)로
작업자 행동 기반 공정 리디자인 시스템을 구상했다.
최대한 주어진 데이터만을 이용한 주제를 구상해보았다.
대충 설명하자면 작업자의 행동 데이터로 패턴을 분석해서
조작이 불편하거나 위험한 동작, 어떤 작업이 비효율적인가를 분석하고
최적화 방안을 제시, 최적화된 공정을 설계하는 시스템이다.
다른 분들도 다양한 아이디어를 제시했고
강사님께서는 접근하는 방식에 대해 강조를 해주셨다.
미니프로젝트 3~4일차에는
AICE 자격증을 위한 대비 프로젝트를 진행했다.
올해부터 국가공인 자격증이 되어서, 국가공인이 된 후
우리가 첫 기수라고 한다.
국가공인이 되고나서 오픈북의 기준이 달라졌다.
Pandas, Scikit-learn, Tensorflow 등 공식 사이트만 참조가 가능하다.
AICE 자격증을 대비하기 위해
EDA 부터 전처리, 머신러닝 / 딥러닝 모델링 등을 진행했다.
전체적인 흐름을 익히는 것을 위주로 진행했고,
자격증을 대비로 한 프로젝트이기 때문에
조원들과 코드를 비교하면서
실제 시험 시 유의사항, 기억해야 할만한 것들을 정리해보았다.
1. 문제 조건 잘 확인하기
2. 시간 배분 잘하기
3. 주석이 달린 답안코드 위치에 정확히 값 넣기
4. 공식사이트 내 코드를 활용하여 작성 가능하도록 미리 연습해보기
5. 다양한 코드들에 익숙해지기 (라이브러리, 모듈 import, 모델링 코드 등등)
6. 모델링의 각 과정에서 쓰이는 함수, 라이브러리 생각하기
7. 각 함수들의 주로 사용하는 옵션 파악하기
8. 의도대로 데이터 처리가 잘 이루어지고 있는지 확인하기
9. 딥러닝 모델 학습 시 회귀, 이진분류, 다중분류에 맞게
활성함수, 손실함수, 평가지표 유의하기
위와 같이 정리해보았다.