Feature Selection
- 가장 좋은 성능을 보여줄 수 있는 데이터의 부분 집합(Subset)을 찾아내는 방법
- 모델 생성에 밀접한 데이터의 부분 집합을 선택하여 연산 효율성 및 모델 성능을 확보
목적 및 필요성
- 연산 효율성
- 특징 생성과는 다르게 원 데이터 공간 내 유의미한 특징을 선택하는 기법으로 연산 효율 및 적절한 특징을 찾기 위해 수행
- 원본 데이터에서 가장 유용한 특징만을 선택하여 간단한 모델 구성 및 성능을 확보하고자 하는 것이 주요 목적
특징 선택 방안
- 필터(Filter)
- 특징들에 대한 통계적 점수를 부여하여 순위를 매기고 선택하는 방법론
- 실행 속도가 빠르다는 측면에서 시간 및 비용 측면의 장점을 보임
- 래퍼(Wrapper)
- 특징들의 조합을 지도학습 기반 알고리즘에 반복적으로 적용하여 특징을 선택하는 방법론
- 최적의 데이터 조합을 찾기 때문에 성능 관점 상 유용하나 시간과 비용 크게 발생
- 조합을 모두 고려하고 성능까지 보기 때문에 필터 방안보다 예측이나 성능 관점에서 유용
- 임베디드(Embedded)
- 모델 정확도에 기여하는 특징들을 선택하는 방법으로 Filter와 Wrapper의 장점을 결합한 방법
- 모델의 학습 및 생성과정에서 최적의 특징을 선택하는 방법
Filter 방식
- 특징들에 대한 통계적 기밥 기반의 점수 및 순위 부여하여 선택
- 카이제곱 필터(Chi-square filter)
- 범주형인 독립 및 종속 변수 간의 유의미성을 도출하기 위한 통계적 방안
- 연속형 변수를 이산화(범주)를 하여 활용 가능

- 상관관계 필터(correlation filter)
- 연속형인 독립 및 종속변수 간 유의미성을 도출하기 위한 통계적 방안
- 보통 임계치(threshold) 설정하여 변수 선택

Wrapper 방식
- 원본 데이터 내 변수 간 조합을 탐색하여 특징 선택
- 반복적 특징 조합 탐색
- 원본 데이터셋 내 변수들의 다양한 조합을 모델에 적용하는 방식
- 최적의 부분 데이터집합(Subset)을 도출하는 방법론
- 대표적인 방식으로 재귀적 특성 제거 (Recursive Feature Elimination)존재
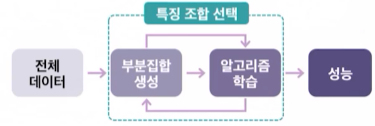
Embedded 방식
- 모델을 학습하여 정확도에 기여하는 특징을 선택하는 방안
- 모델 기반 특징 선택
- 알고리즘 내 자체 내장 함수로 특징을 선택하는 방식으로, 모델 성능에 기여하는 특징을 도출
- 모든 조합을 고려하고 결과를 도출하는 Wrapper와 달리 학습과정에서 최적화된 변수를 선택
- 트리 계열 모델 기반의 특징 선택이 대표적(랜덤포레스트 기반 Feature Importance 기반)

특징 선택 알고리즘
- 랜덤포레스트 모형 기반의 알고리즘
- 보루타 알고리즘(Boruta Algorithm)
- Boruta Algorithm은 기존 데이터 임의로 복제하여 랜덤 변수(shadow) 생성하고 원 자료와 결합하여 랜덤 포레스트 모형에 적용
- shadow보다 중요도가 낮을 경우 중요하지 않은 변수로 판단 후 제거
'[KT] AIVLE School > 사전학습' 카테고리의 다른 글
| 데이터 탐색 이해와 실무 (2) - 일변량 시각화 탐색 (0) | 2025.03.17 |
|---|---|
| 데이터 탐색 이해와 실무 (1) - 일변량 비시각화 탐색 (1) | 2025.03.17 |
| 데이터 전처리 이해와 실무 (4) - 데이터 변환 : 특징 생성 (1) | 2025.03.16 |
| 데이터 전처리 이해와 실무 (3) - 데이터 변환 : 정규화, 구간화 (2) | 2025.03.16 |
| 데이터 전처리 이해와 실무 (2) - 데이터 정체 : 이상 데이터 처리 (1) | 2025.03.16 |