[KT] AIVLE SCHOOL 7일차
회귀 모델 평가
- 회귀 모델이 정확한 값을 예측하기는 사실상 어려움
- 예측 값과 실제 값에 차이(=오차)가 존재할 것이라 예상함
- 예측 값이 실제 값에 가까울 수록 좋은 모델이라 할 수 있음
- 예측한 값과 실제 값의 차이(=오차)로 모델 성능을 평가
- 오차를 줄여야 함 (작을수록 좋음)

- MSE(Mean Squared Error)
- 오차 제곱(SSE)의 합을 구한 후 평균을 구함 (자주 사용)
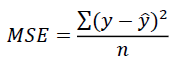
- 오차 제곱(SSE)의 합을 구한 후 평균을 구함 (자주 사용)
- RMSE(Root Mean Squared Error)
- 오차의 제곱이므로 루트를 사용해 일반적인 값으로 표현

- 오차의 제곱이므로 루트를 사용해 일반적인 값으로 표현
- MAE(Mean Absolute Error)
- 오차 절대값의 합을 구한 후 평균을 구함

- 오차 절대값의 합을 구한 후 평균을 구함
- MAPE(Mean Absolute Percentage Error)
- 오차 비율을 표시하고 싶은 경우 사용
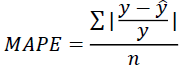
- 오차 비율을 표시하고 싶은 경우 사용
결정 계수 R² (R-Squared)
- Coefficient of Determination
- MSE로 여전히 설명이 부족한 부분이 있음(성능이 확실히 와 닿지 않음)
- 모델 성능을 잘 해석하기 위해서 만든 MSE의 표준화된 버전
- 전체 오차 중에서 회귀식이 잡아낸 오차 비율(일반적으로 0 ~ 1 사이) (클 수록 좋음)
- 오차의 비 또는 설명력이라고도 부름
- R² = 1이면 MSE = 0 이고 모델이 데이터를 완벽하게 학습한 것

- SST(Sum Squared Total) : SST= SSR + SSE / 실제값과 평균의 차이의 제곱
- SSR : SSR = SST - SSE / 평균과 모델의 예측값의 차이의 제곱
- 우리 모델이 평균보다 더 많이 해결해낸 것
'Data Science > 머신러닝' 카테고리의 다른 글
| 모델 성능 튜닝 (1) | 2025.04.03 |
|---|---|
| 머신러닝 알고리즘 (0) | 2025.04.03 |
| 모델 성능 평가(분류) (0) | 2025.04.03 |
| 머신러닝 모델링 (0) | 2025.04.03 |