[KT] AIVLE SCHOOL 8일차
AI, ML(머신러닝), 딥러닝

머신러닝
전체 Process(CRISP-DM)
- AI, Data를 기반으로 한 비즈니스 문제해결 방법론(절차)
- 무엇이 문제인가?
- 문제가 해결 되었는가?
- Business Understanding
- 비즈니스 문제정의
- 데이터분석 방향, 목표
- 초기 가설 수립 / x -> y
- Data Understanding
- 원본식별
- 분석을 위한 구조 만들기
- 데이터분석 EDA & CDA
- Data PreParation
- 모델링을 위한 데이터 구조 만들기
- 모든 셀은 값이 있어야 함
- 모든 값은 숫자여야 함
- (필요 시) 숫자의 범위가 일치
- 모델링을 위한 데이터 구조 만들기
- Modeling
- 모델을 만들고 검증
- Evaluation
- 기술적 관점 평가
- 비즈니스 관점 평가
- Deployment
- 모델 관리
- AI 서비스 구축
모델과 모델링
- 패턴
- 데이터 안에는 패턴이 담겨 있음
- 패턴이 전혀 없는 데이터 -> 노이즈
- 모델(Model)
- 모델 : 데이터로부터 패턴을 찾아, 수학식으로 정리해 놓은 것
- 모델링 : 가능한 오차가 적은 모델을 만드는 과정
- 모델의 목적 : 샘플을 가지고 전체를 추정
- 샘플 : 표본, 부분집합, 일부, 과거의 데이터(우리가 들고 있는 데이터)
- 전체 : 모집단, 전체집단, 현재와 미래의 데이터
- 추정 : 예측, 추론
- 모델의 성능 평가
- 모델의 성능은 오차(error)를 통해 계산됨
- 모델링: train error를 최소화 하는 모델을 생성하는 과정
- 모델 튜닝: validation error를 최소화 하는 모델 선정
- 평가 지표
- 회귀 모델
- MSE, RMSE, MAE : 오차의 양
- MAPE : 오차율
- R2 Score : 결정계수
- 분류 모델
- Confusion Matrix
- Accuracy : 정분류율
- Recall : 재현율
- Precision : 정밀도
- F1 - Score : Recall과 Precision의 조화평균
- Confusion Matrix
- 회귀 모델
- 모델의 성능은 오차(error)를 통해 계산됨
머신러닝과 딥러닝의 차이
- 기존 sklearn 기반 머신러닝 모델링과 딥러닝은 다음과 같은 차이가 있음
| 구분 | 머신러닝 (ML) | 딥러닝 (DL) |
| 정의 | 데이터를 이용해 명시적 프로그래밍 없이 학습하는 알고리즘 | 인공신경망(특히 다층 신경망)을 사용하는 머신러닝의 하위 분야 |
| 특징 | 특징(Feature)을 사람이 직접 설계해야 함 | 특징을 스스로 자동으로 추출함 (end-to-end 학습) |
| 예시 알고리즘 | 결정트리, SVM, k-NN, 로지스틱 회귀 등 | CNN, RNN, Transformer 등 |
| 데이터 요구량 | 비교적 적은 양의 데이터로도 동작 가능 | 매우 많은 데이터가 필요함 |
| 연산량 / 하드웨어 | 상대적으로 적음, CPU만으로도 학습 가능 | 높은 연산량, GPU 같은 고성능 하드웨어 필요 |
| 성능 | 복잡한 문제에선 한계 있음 | 이미지/음성/언어 등 복잡한 문제에서 뛰어난 성능 |
| 적용 예시 | 이메일 스팸 분류, 고객 이탈 예측 | 자율 주행, 음성 인식, 챗봇, 번역 등 |
- 가장 중요한 차이
- 머신러닝은 새로운 feature를 추출하는 과정이 중요하게 다뤄짐 (Feature Engineering)
- 딥러닝은 각 레이어를 통해 모델 안에서 자동으로 새로운 feature가 추출됨
딥러닝 코드 구조
- 데이터 전처리
- 전처리 1
- NaN(결측치) 처리
- 가변수화
- 스케일링
- 데이터 분할
- 전처리 2
- 텐서로 변환
- Data Loader(train set)
- 전처리 1
- 모델링
- 모델 설계
- Loss, Optimizer
- 학습
- 학습 곡선 검토
- 예측 및 검증 평가
가변수화
- 범주 -> 숫자 : 가변수화
- 데이터는 머신러닝 알고리즘에 사용하려면 숫자로 변환해야 함
- One-Hot-Encoding
- get_dummies()
스케일링
- 딥러닝은 스케일링을 필요로 함
- 방법 1. Normaliztion(정규화) : 모든 값의 범위를 0 ~ 1로 변환
- 방법 2. Standardization(표준화) : 모든 값을 평균 0, 표준편차 1로 변환
Tensor
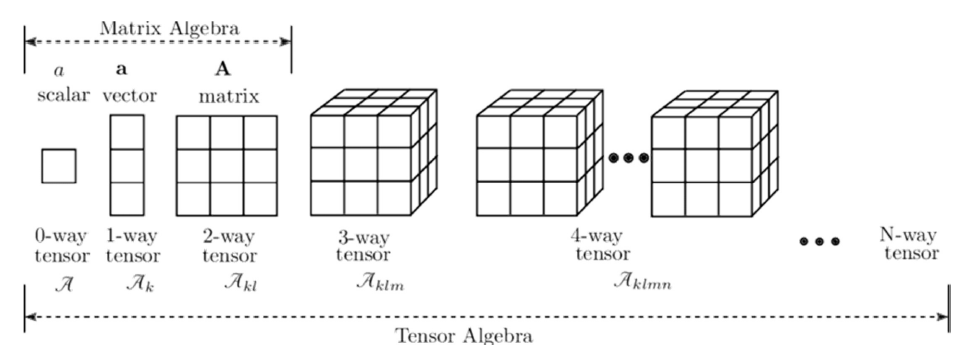
- PyTorch에서의 텐서 사용
- GPU 가속
- 텐서는 GPU에서 실행될 수 있는 데이터 구조(CUDA를 통해 NVIDIA GPU 지원)
- 넘파이 어레이는 기본적으로 CPU에서만 작동
- 자동 미분
- 파이토치 텐서는 자동 미분(autograd) 기능 내장
- 효율적인 메모리 관리
- 텐서는 메모리 효율성과 성능 면에서 최적화되어 있음
- GPU 가속
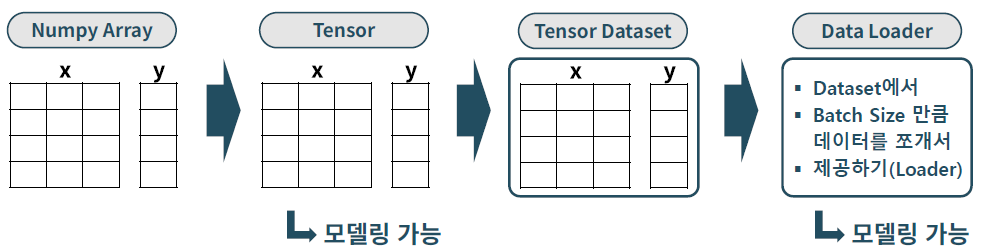
Data Loader
- PyTorch 모델링을 위해서 필요한 자료형
- PyTorch는 Tensor나 TensorDataset을 요구
- Tensor: 텐서로 변환된 x와 y를 이용해서 학습 가능 (Tensor로 만들어야만 학습 가능)
- Data Loader: 텐서 데이터셋을 미니배치(묶음) 단위로 순차적으로 뽑아 학습에 사용하도록 제공
가중치 조정
- 파라미터 업데이트라고도 부름
- 1 ~ 3월의 판매량으로 4월의 판매량을 예측
- 1, 2, 3월 판매량의 평균으로 4월 판매량을 예측할 때
- 1/3 * 1월 + 1/3 * 2월 + 1/3 * 3월
- 1/3 = w , w를 가중치(weight)라고 부름
- 좀 더 정확하게 예측하는 방법
- 1, 2, 3월의 판매량은 똑같이 중요한가?
- 월별로 중요도를 달리 했을 때 가중치를 어떻게 정해주는 게 좋을까?
- 가중치가 1, 2, 3 중 어느 것이 제일 클까?(중요할까?)
- 최적의 Weight를 어떻게 찾을까?
- 최적의 모델이란 오차가 가장 적은 모델을 의미
- 조금씩 weight를 조정하며 오차가 줄어드는지를 확인한다.
- 지정한 횟수만큼 혹은 더 이상 오차가 줄지 않을 때까지 반복한다.
- 학습한다는 것은 오차를 최소화 하는 파라미터(가중치) 값을 찾는다는 의미
- -> 모델링의 목표
- 1, 2, 3월 판매량의 평균으로 4월 판매량을 예측할 때
e.g. lstat(하위계층 비율)로 medv(집값) 예측
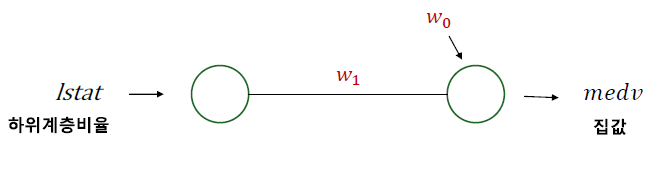
- 어떤 정보를 O로 표현, O을 node(unit) 혹은 뉴런(Neuron)이라고 부르기도 함
- 이를 수식으로 적으면 아래와 같음
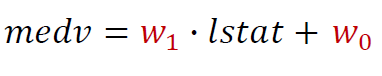
딥러닝 학습 절차
- 가중치 초기값을 할당한다. (초기 모델을 만든다.)
- (초기)모델로 예측한다.
- 오차를 계산한다. (loss function)
- 가중치 조절 : 오차를 줄이는 방향으로 가중치를 적절히 조절한다.(optimizer)
- 적절히 조절 -> 얼마만큼 조절할 지 결정하는 하이퍼파라미터 : learning rate (lr)
- 다시 처음으로 가서 반복한다.
- 전체 데이터를 적절히 나눠서(mini batch) 반복 : batch_size
- 전체 데이터를 몇 번 반복 학습할 지 결정 : epoch
'Data Science > 딥러닝' 카테고리의 다른 글
| CNN (0) | 2025.04.08 |
|---|---|
| Early Stopping와 Dropout (0) | 2025.04.08 |
| 모델 성능 최적화 (0) | 2025.04.07 |
| 분류 모델링(Classification) (0) | 2025.04.07 |
| 회귀 모델링(Regression) (0) | 2025.04.04 |