[KT] AIVLE SCHOOL 9일차
모델링의 목적
- 학습용 데이터에 있는 패턴으로 그 외 데이터(모집단 전체)를 적절히 예측
- 학습한 패턴(모델)은 학습용 데이터를 잘 설명할 뿐만 아니라 모집단의 다른 데이터(val, test)도 잘 예측해야 함
모델의 복잡도
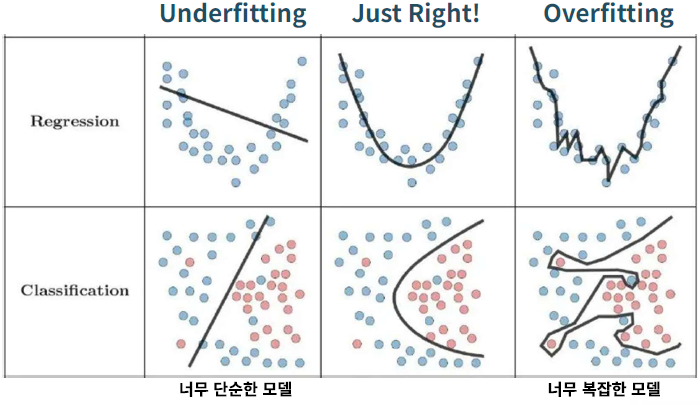
- 너무 단순한 모델 : train, val 성능이 떨어짐
- 적절히 복잡한 모델 : 적절한 예측력
- 너무 복잡한 모델 : train 성능이 높고 val 성능이 떨어짐
- Underfitting, Overfitting
- 모델(알고리즘)마다 복잡도를 결정하는 요인이 있음
- 오캄의 면도날
- 가능한 한 단순한 모델이 가장 좋은 모델이다
- 성능이 유지되면서 가장 단순한 모델이 가장 좋은 모델이다
- 과적합(Overfitting)
- 모델이 복잡해지면 가짜 패턴(혹은 연관성)까지 학습하게 됨
- 가짜 패턴
- 학습 데이터에만 존재하는 패턴
- 모집단 전체의 특성이 아님
- 학습 데이터 이외의 데이터셋에서는 성능 저하
- 모델의 복잡도 : 학습용 데이터의 패턴을 반영하는 정도
- 모델(알고리즘)마다 복잡도를 결정하는 요인이 있음
적절한 모델을 만드는 방법
- 적절한 복잡도 지점 찾기
- 알고리즘(모델)마다 각각 복잡도 조절 방법이 있음
- 복잡도를 조금씩 조절해 가면서 (보통 하이퍼파라미터 조정)
- train error와 vlidation error를 측정하고 비교 (관점은 validation error)
- 딥러닝에서 조절할 대상
- Epoch와 learning_rate
- 모델 구조: hidden layer 수, node 수
- 과적합을 해결하기 위한 방법
- 미리 멈춤 (Early Stopping)
- 임의 연결 끊기 (Dropout)
- 가중치 규제하기 (Regularization(L1, L2))
딥러닝의 복잡도
- hidden layer 수 : Layer가 많을수록 복잡
- node 수 : node가 많을수록 복잡
- 딥러닝 모델의 복잡도 혹은 규모와 관련된 수 : 파라미터(가중치) 수
- input feature 수, hidden layer 수, node 수와 관련 있음
- Conv Layer인 경우 MaxPooling Layer를 거치면 데이터가 줄어들어 파라미터 수 감소
- 파라미터 수가 많을 수록 복잡한 모델, 연결이 많은 모델, 파라미터가 아주 많은 언어 모델(LLM, Large Language Model)
- 파라미터 수 확인 : torchsummary 라이브러리의 summary 함수 사용
'Data Science > 딥러닝' 카테고리의 다른 글
| CNN (0) | 2025.04.08 |
|---|---|
| Early Stopping와 Dropout (0) | 2025.04.08 |
| 분류 모델링(Classification) (0) | 2025.04.07 |
| 회귀 모델링(Regression) (0) | 2025.04.04 |
| 딥러닝 개요 (0) | 2025.04.04 |