[KT] AIVLE SCHOOL 8일차
Process
- 각 단계(Task)는 이전 단계의 Output을 Input으로 받아 처리한 후 다음 단계로 전달

- 예 : 상품기획 -> 디자인 -> 생산 -> 물류입고 -> 매장판매
딥러닝 구조
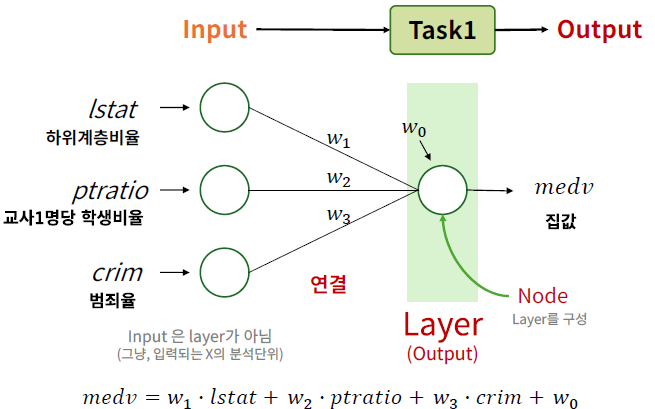

- Output Layer : 출력층, 출력 결과(Output)을 만들어내는 Layer
- Hidden Layer : 은닉층, Input과 Output Layer 사이에 있는 Layer
Loss function
- 오차함수, 손실함수, 목적함수
- 학습 목적을 결정 : 이 값을 최소화/최대화 하는 것이 목적
- 회귀모델
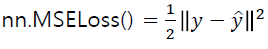
- 모델을 검증 평가할 때의 MSE와 학습 시 목적함수에서의 MSE는 의미는 같으나 계산식이 약간 다름
- 모델 검증평가 때 MSE

- 모델 검증평가 때 MSE
- 모델을 검증 평가할 때의 MSE와 학습 시 목적함수에서의 MSE는 의미는 같으나 계산식이 약간 다름
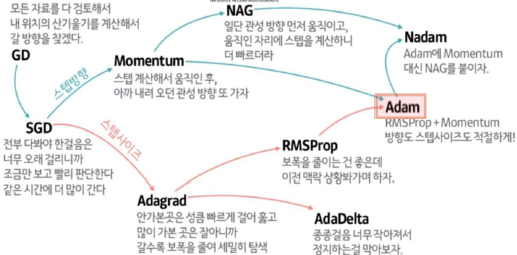
Optimizer
- 오차를 최소화 하도록 가중치를 업데이트하는 역할
- Adam : 최근 딥러닝에서 가장 성능이 좋은 Optimizer로 평가됨
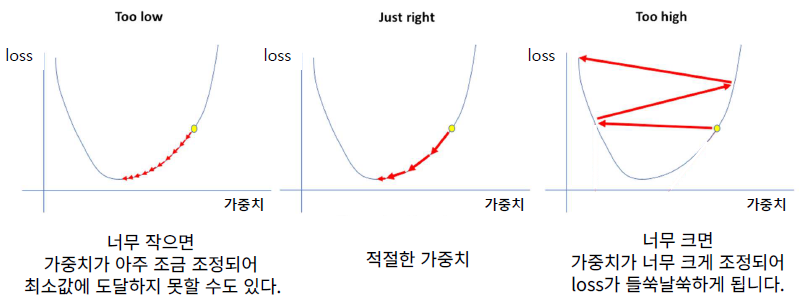
- lr : learning_rate
- 업데이트 할 비율
- 기울기(gradient)에 곱해지는 조정 비율 (걸음걸이의 '보폭'을 조정한다고 표현)
batch_size
- 전체 데이터를 적절히 나눠서(mini batch) 배치 단위로 학습(가중치 업데이트)
- Data Loader 생성 시 batch_size 지정
- 기본값 : 32, 특별한 경우가 아니라면 보통 32로 지정
- 학습 데이터 크기를 감안하여 지정 (데이터가 많으면 32보다 크게)
from torch.utils.data import DataLoader
train_loader = DataLoader(train_dataset, batch_size = 32, shuffle = True)
# shuffle : 데이터를 섞어서 배치 단위로 분할
Epoch
- 주어진 train set을 몇 번 반복 학습할 지 결정
- 만약 Epoch = 10
- train set을 10번 반복해서 학습하면서 최적의 가중치를 찾는다.
- Epoch의 수 찾기
- 최적의 값은 케이스마다 다름
- 하이퍼파라미터
- 모델 학습시, 사람이 정해 주어야 하는 옵션, 다양한 값으로 시도해보고 검증 평가를 통해서 최적의 값을 찾는 과정을 '하이퍼파라미터 튜닝' 이라고 함
학습 곡선
- 모델 학습이 잘 되었는지 파악하기 위한 그래프
- 정답은 아니지만 경향을 파악하는데 유용
- 각 Epoch 마다 train error와 val error가 어떻게 줄어들고 있는지 확인
- Epoch = 10 : train data를 10번 반복 학습
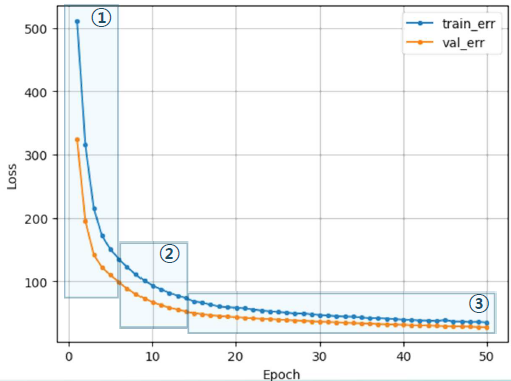
- 바람직한 학습 곡선
- 초기 epoch에서는 오차가 크게 줄고 오차 하락이 꺾이면서 점차 완만해짐
- 학습곡선의 모양새는 다양함
- 바람직하지 않은 학습 곡선
- Case 1 : 학습이 덜됨, 오차가 줄어들다가 학습이 끝남
- 조치 : epoch 수를 늘리거나 learning rate을 크게 한다.

- 조치 : epoch 수를 늘리거나 learning rate을 크게 한다.
- Case 2 : train_err가 들쑥날쑥, 가중치 조정이 세밀하지 않음
- 조치 : learning rate을 작게

- 조치 : learning rate을 작게
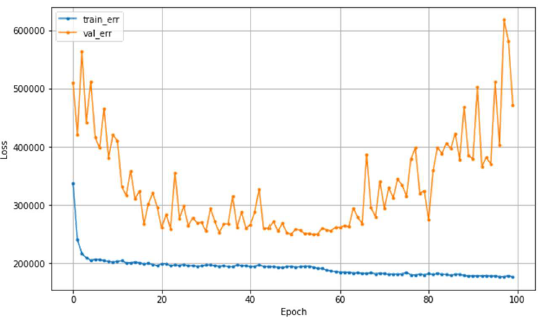
- Case 3 : 과적합, train_error는 계속 줄어드는데 val_error는 어느 순간부터 커지기 시작,
- 너무 과도하게 학습이 된 경우
- 조치 : Epoch 수 줄이기
- Case 1 : 학습이 덜됨, 오차가 줄어들다가 학습이 끝남
Hidden Layer 추가
- Input과 Output Layer 사이의 모든 Layer는 Hidden Layer
- Hidden Layer를 추가하면 한번 더 생각 한다는 느낌으로 이해

n_feature = x.shape[1] # 12개
# 모델 구조 설계
model3 = nn.Sequential(
nn.Linear(n_feature, 2), # 은닉층
nn.ReLU(), # 활성함수
nn.Linear(2, 1), # 출력층
).to(device)
print(model3)- nn.Linear 함수 레이어를 빽빽하게 모두 연결되었다고해서 Fully Connected Layer 혹은 Dense Layer 라고 부름
- 첫 은닉층에서 오른쪽 레이어로 갈수록 점차 줄여감 (정답은 없음, 늘렸다가 줄일 수도 있음)

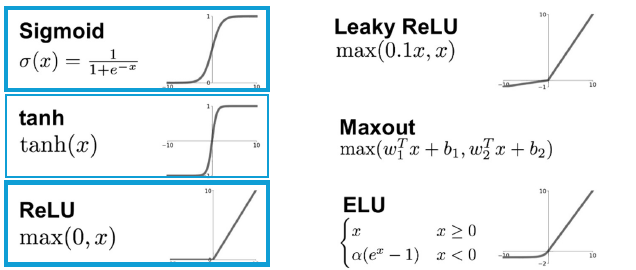
활성화 함수
- 현재 레이어(각 노드)의 결과값을 다음 레이어(연결된 각 노드)로 어떻게 전달할지 결정/변환해주는 함수
- 함수는 변환해준다 !
- 만약 활성화 함수가 없으면 은닉층을 아무리 추가해도 그냥 선형회귀(선형함수)
- 그래서 활성화 함수는 Hidden Layer에서는 이런 선형함수를 비선형 함수로 변환해 주는 역할이고
- Output Layer에서는 결과 값을 다른 값으로 변환해 주는 역할
- (ReLU 함수를 많이 씀!)
'Data Science > 딥러닝' 카테고리의 다른 글
| CNN (0) | 2025.04.08 |
|---|---|
| Early Stopping와 Dropout (0) | 2025.04.08 |
| 모델 성능 최적화 (0) | 2025.04.07 |
| 분류 모델링(Classification) (0) | 2025.04.07 |
| 딥러닝 개요 (0) | 2025.04.04 |